Tests verify contracts. Probes verify reality.
A working SSE parser. Hundreds of unit tests passing. Recorded fixtures from three production providers. CI clean. Then a live API call returns HTTP 200, the stream completes, and the parser produces zero events. The system reports success. The output is wrong.
This is the kind of bug that survives every contract test written for it. It does not live in any single component. It lives in the assumptions between the code, the tests, and the runtime, where reality and report diverge silently and nothing in the status tells you they diverged. After enough of these, a pattern starts to emerge in how developers and agents are responding to them. This document is about that pattern.
A Claude plugin accompanies this essay: github.com/AmirShayegh/probe-loop. Install it and run the loop on your own codebase; the code is where the practice lives, this is the writing about it.
01 /The thing we are all already doing
Something is happening in agentic coding that does not have a name yet. It looks like this. The architecture is done. The unit tests are green. CI is clean. And the developer, working with an agent, opens a session that has nothing to do with adding features. They ask the agent to run the system. Submit a real operation through the real interface. Capture the actual output. Compare it against what the system claimed to do. Find the seams where reality and report diverge. Fix the root cause. Lock it in.
I keep seeing adjacent versions of this pattern appear in agentic coding workflows. It is not exploratory testing in the QA sense, because the developer and the agent are doing it together, in the same loop, with full architectural context, and the probe that finds a bug becomes the regression gate that closes it. It is not test-driven development, because nothing is being driven by the test. The system already exists. The probes are not contracts. They are experiments.
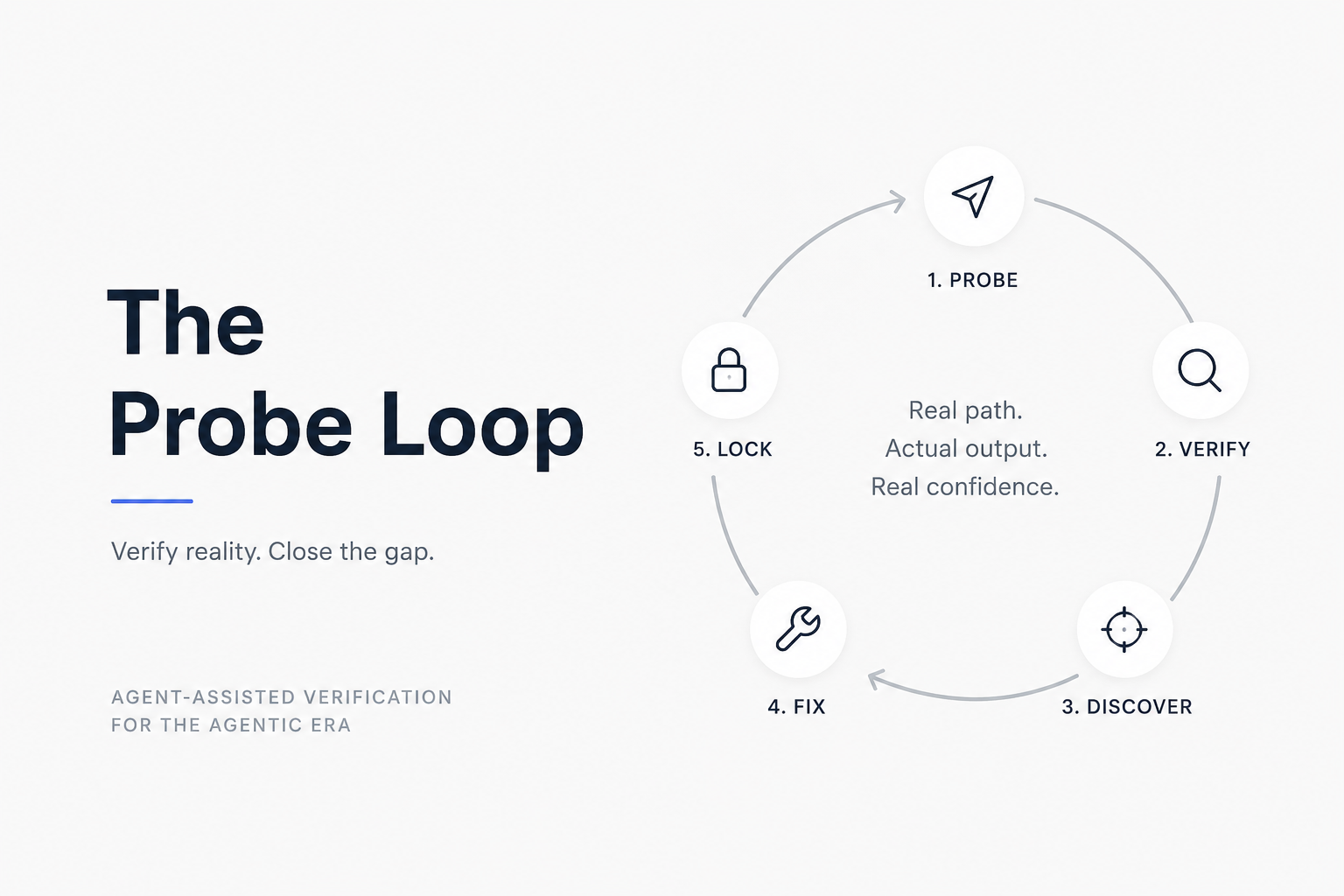
It is a loop. The probe loop.
A probe loop is an agent-assisted verification pass where a developer exercises the real production path, independently checks the real output, traces any divergence to its root cause, and turns the same probe into a regression gate.
This document is an attempt to name what is already being assembled, lay out its shape, and explain why the practice has only just become affordable. None of the individual ideas here are new. Independent verification of output is old. Exploratory testing is old. End-to-end integration testing is old. What is new is the economics. The probe loop is what those ideas become when an agent can carry enough of the codebase in context to close the full cycle in a single session.
02 /The shape of the loop
The probe loop has five stages, executed in sequence, almost always inside one continuous session.
Probe. Submit a real operation through the real production path. Cross every layer boundary. No mocks where the seam matters. No fixtures where the environment matters. Real production path does not always mean live production data. It means the same runtime, provider, stream, file, network, or integration seam the user path depends on.
Verify. Do not trust what the system reports. Read the actual output. Compare it independently against what the operation should have produced. Status codes are not verification. Logs are not verification. Bytes are verification. Pixels are verification. Stream events are verification.
Discover. The gap between what the system reports and what it actually does is where the bug lives. The reported value is usually correct in some narrow contract sense. The actual behavior diverges at a boundary nobody tested across.
Fix. Trace the divergence to its root layer, which is rarely the layer that surfaced the symptom. Fix the cause, not the symptom. Hold the whole stack in working memory long enough to know which layer is actually responsible.
Lock. The probe that found the bug becomes the regression test. The behavior becomes a permanent assertion against the actual production path, not a fixture in a sandbox.
A loop, not a methodology. You do not "do probe loops" the way teams once "did TDD." You run a probe loop when you are asking the question: does this actually work? That question does not have a place in the TDD cycle. It does not appear in the typical sprint. It is the question that has historically been answered slowly, expensively, and incompletely, by QA teams or by users in production. Agents change that.
03 /Why now
The probe loop has always been the right thing to do. Any QA engineer with a decade of scars will recognize its shape. What kept it from becoming a routine developer practice was cost. The full loop, run by a human, looks like this: read enough of the codebase to know which paths to probe. Set up the environment. Write the probe. Run it. Watch it fail in some unintelligible way. Switch to the debugger. Switch to the network inspector. Switch back to the code. Trace the failure across four or five layers. Find the root cause. Write the fix. Verify the fix did not break anything else. Convert the probe into a regression test. Write enough documentation that the next person understands what was being tested.
Each context switch costs minutes. Each layer crossed costs more. Doing this comprehensively across a codebase is the kind of effort that gets put off until a production incident forces it. Most organizations never do it at all, because the economics never close.
An agent collapses the loop. The probe author, the probe runner, the failure investigator, the root-cause analyst, and the regression-test writer are now one actor, with one set of context, working at machine speed. Reading the full codebase to identify untested seams is no longer days of work. Generating targeted probes against those seams is no longer a backlog item. Tracing a failure across six layers does not require the operator to hold six layers in their head, because the agent already has them in context. The loop closes inside a single session that takes minutes, not weeks.
This is the substrate change. The probe loop is not a new idea. It is an old idea that has finally become affordable. What was once a heroic effort by a senior engineer with a clear weekend is now a routine pass that can be run by a developer who can frame the right question and judge the answer, paired with a competent agent.
This is what is making the practice converge across the agentic coding community. Not a shared methodology. A shared economic reality.
04 /A prompt I actually use
The workflow can be as direct as one instruction at the start of a session:
Exercise the real path for this feature. Do not trust status codes or logs as proof. Capture the actual output. Compare it to the intended result. Find the first layer where reality diverges from what the system reports. Fix the root cause, then add a regression check that would have failed before the fix.That prompt is not magic. It just forces the session to care about output rather than vibes. Without it, an agent may stop at "tests pass." With it, the agent has to prove the system did the thing.
05 /Tenets
The system reports what it claims, not what it does.
The seams between correct components are where the surviving bugs live.
A status code is not a verification. A log line is not a verification. The output is the verification.
The bug is rarely in the layer that surfaced it.
The probe that found the bug is the regression gate that closes it.
The agent closes the loop. The developer sets the question.
06 /The bug taxonomy
The probes catch a specific class of bug. After enough loops, the failures cluster into recognizable categories. Each category is a structural blind spot of contract-level testing. The taxonomy is the most portable piece of this document. Take it whether or not you take the rest.
Silent no-op. The operation completes successfully and has no effect. Output equals input. Status reports success. Only independent verification of the output catches it. Example: a pipeline stage mapped to a passthrough that copies the input unchanged while reporting "completed."
Environment mismatch. The code is correct against its specification and broken against the actual runtime. The test environment and the production environment differ in a way the developer did not anticipate. Example: an SSE parser that uses empty lines as event boundaries and works against every recorded fixture, but the production runtime strips empty lines from HTTP streams before the parser ever sees them.
Swallowed error. A failure path discards the diagnostic, catches and ignores the error, or reports success with truncated output. The system may report failure (good) but lose the reason (bad), or worse, report success with corrupted output. Example: an encoder receive loop that uses break where it should use throw, producing truncated files marked as completed.
Hardcoded parameter. A value that should come from configuration is hardcoded. The code works for the hardcoded case and silently produces wrong output for every other case. Tests pass because the fixtures use the hardcoded value. Example: a transcoding executor that hardcodes its output container format and silently produces the wrong wrapper for every other requested format.
Cross-layer trust violation. Layer A assumes Layer B handles something. Layer B assumes Layer A handles it. Neither does. Each layer passes its own tests because the tests do not cross the boundary. Example: a safety-limits subsystem that protects the standard execution path and is bypassed entirely by an alternate provider-driven path that nobody thought to guard.
Destructive edge case. A code path that is safe for the common case destroys data in an edge case nobody probed for. The edge case is obvious in retrospect but invisible until it is named. Example: an atomic-output pattern that writes to a temporary file and replaces the original, with no guard against the case where source and output paths are the same.
Every entry in this taxonomy shares a structural property. The bug lives in the gap between what the system reports and what it actually does. That gap is invisible to any test that only checks the report. Closing it requires a probe that reads the result.
07 /When to run a probe loop
The loop earns its cost in specific situations. Run one when:
- A feature crosses provider, runtime, file, stream, or network boundaries.
- The tests are green but the output is not directly inspected.
- The fixtures represent the API contract, but not the live runtime.
- An agent generated code that appears correct but has not been exercised through the real path.
- The system reports success before anyone has inspected the artifact.
- A new layer was added without verifying that existing safety, timeout, or cancellation guarantees still cross it.
- The architecture has settled and the next user-visible failure is now more expensive than the next probe.
If none of these apply, contract-level tests are doing their job. If any of them do, the probe loop is the cheapest tool left in the box.
08 /What this is not
The probe loop has ancestors. Naming them is part of being honest about what is new.
Exploratory testing is the closest philosophical ancestor. Fowler's framing, the QA literature, the whole tradition of "test with your hands, not your fixtures," is the same instinct. The difference is that exploratory testing has historically been a QA practice, executed against a built system by a tester who is not the developer, with limited architectural visibility and no path to lock regressions immediately. The probe loop is the same instinct performed by the developer with the agent, with full codebase context, where the probe-to-regression cycle closes in the same session.
End-to-end testing verifies a known flow against expected behavior. It is the artifact. The probe loop is the investigative cycle that produces the artifact: discovering which real flows need verification, finding where report and reality diverge, fixing the root cause, and converting the discovery into a permanent end-to-end regression. E2E tests are what get left behind. The probe loop is the work that decides which ones should exist.
Characterization testing captures what existing code actually does, as a baseline before refactoring legacy systems. It is about preserving current behavior, not interrogating whether current behavior is correct. The probe loop assumes current behavior is suspect and verifies it against intent.
Metamorphic testing verifies relationships between outputs when exact expected outputs are hard to know. Useful, more academic, oracle-focused. The probe loop is closer to direct output verification than to relational reasoning.
Older usage of the word "probe" exists in software testing. A 2014 blog post described "sending a probe" as an alternative to mocks for integration discovery. Academic literature uses "probe-based testing" for instrumentation-based observation of internal execution. These are kin, not the same animal. The probe loop is not a single technique. It is a closed cycle that finishes in a regression gate.
A 2015 paper coined "Proof-Driven Development" (PDD) for an extension of TDD using dependently typed programming. Different content, similar etymology, never culturally adopted. Worth acknowledging so the search results do not get confused.
The probe loop is what these older practices become when the loop closes inside one context, at agent speed, for the cost of an evening session.
09 /What this does not replace
TDD remains the right practice for new code development. The probe loop has nothing to say about how to design an interface, structure a module, or drive a green test from a red one. Contracts are still contracts. Unit tests are still the right way to verify them.
Type systems remain the right tool for compile-time guarantees. Code review remains the right tool for design quality. Static analysis catches what static analysis catches.
The probe loop is additive. It is the pass you run after the contracts are green and the architecture is settled, when the question becomes: does this actually work end-to-end, against the real runtime, with no fixtures hiding the seams? That question was always worth asking. What changed is that it is now affordable to ask it comprehensively, and to answer it before users do.
10 /A note on the convergence
What is happening is not the standardization of a term. It is the appearance of adjacent practices around the same pressure point. Agents are being used not only to implement software, but to interrogate whether the software actually did what it claimed.
There is now empirical research studying agentic coding manifests across hundreds of public repositories, and a growing set of practitioner-maintained best-practice repositories describing patterns that overlap closely with the loop described here. The practice is appearing in the wild whether or not anyone has named it.
The probe loop closes the gap between contract correctness and runtime correctness. It runs when the architecture is settled, the tests are green, and the question becomes whether the system works against the real thing rather than against its specification. It catches the bug classes that survive contract testing: silent no-ops, environment mismatches, swallowed errors, hardcoded parameters, cross-layer trust violations, destructive edge cases. It produces regression gates against the real production path, not against fixtures. Its cost has collapsed because the agent can carry the codebase, the failure trace, and the regression-test draft inside a single context.
Tests verify contracts. Probes verify reality.
11 /References
- github.com/AmirShayegh/probe-loop. Claude plugin that runs the practice end-to-end inside a Claude Code session.
- On the Use of Agentic Coding Manifests: An Empirical Study of Claude Code. An empirical study of 253 Claude.md files from 242 repositories, filtered from an initial search of 838 files across 806 repositories created between February and June 2025. arxiv.org/abs/2509.14744
- Claude Code Best Practices. A practitioner-maintained collection of agentic coding patterns, including cross-model QA workflows. github.com/shanraisshan/claude-code-best-practice
- Proof-Driven Development (Goodspeed, 2015). An earlier coinage of the acronym PDD for a TDD extension using dependently typed programming. Different content, similar etymology. arxiv.org/abs/1512.02102
- Sending a Probe (2014). A blog post describing "probe" testing as an alternative to mocks for integration discovery. Conceptually adjacent to the loop described here.
- Exploratory Testing (Fowler). The closest philosophical ancestor of the probe loop in the QA tradition. martinfowler.com/bliki/ExploratoryTesting.html